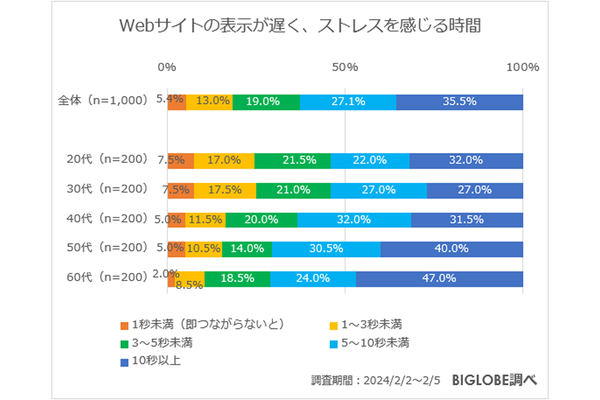
本記事はJani Hartikainen、Florian Rappl、Jezen Thomas、Jeff Smithが査読を担当しています。最高のコンテンツに仕上げるために尽力してくれたSitePointの査読担当者のみなさんに感謝します。
現在のブラウザーはほぼすべて、WebサイトでのPDF文書を閲覧できる機能を最初からサポートしています。しかし、開発者はこのもともと備わっている機能を制御できません。たとえば、Webアプリ側のルールでPrintボタンを無効にしたい場合、有料会員への移行ページだけをレンダリングしない場合などを考えてみます。embedタグを使えばブラウザーにもともと備わっているPDFレンダリング機能を利用できますが、プログラムへアクセスできないので、ニーズを満たすようにレンダリングを制御できません。
うれしいことに現在は、ブラウザーでPDF文書をレンダリングできるMozilla LabsのPDF.jsがあります。何より重要なのは、開発者が希望通りにPDF文書のレンダリングを完全に制御できることが挙げられます。
では、PDF.jsとは一体どのようなものかを説明していきます。
PDF.jsとは何か
PDF.jsは、HTML5をベースとする技術を元に作られたPDFレンダリングエンジンです。つまり、サードパーティープラグインを一切インストールすることなく、現在のブラウザー上でPDFを利用できるということです。
PDF.jsは、 Dropbox、CloudUp、Jumpshareなどのオンラインファイル共有サービスを含めて、すでにさまざまな場所で利用されており、ユーザーはブラウザーにもともと備わっているPDFレンダリング機能に頼ることなくPDF文書をオンラインで閲覧できます。
PDF.jsは、間違いなくWebアプリで使うには素晴らしく、必須のツールですが、PDF.jsを組み込むのは、思っているほど簡単ではありません。テキストレイヤーまたは注釈(外部や内部リンク、または両方)をレンダリングしたり、パスワードで保護されたファイルをサポートするなど、ある種の機能を組み込む方法のドキュメントがほとんどないからです。
この記事では、PDF.jsについて解説し、どうすれば異なった機能を組み込めるかを説明します。今回は、以下の内容を紹介します。
- 組み込みの基本
- SVGを利用してのレンダリング
- テキストレイヤーのレンダリング
- 拡大・縮小
組み込みの基本
必要なファイルをダウンロードする
PDF.jsは、その名が示すとおり、ブラウザー上でPDF文書をレンダリングするために利用するJavaScriptライブラリーです。最初に、適切に動作しているPDF.jsが要求する必要なJavaScriptファイルを入手します。以下はPDF.jsが要求する2つの中心となるファイルです。
- pdf.js
- pdf.worker.js
この2つファイルを入手するには、Node.jsのユーザーであればGitHub上にあるステップに従います。gulp genericコマンドを入力して、必要なファイルを入手します。
しかし、たとえば私のようにNode.jsのユーザーになりたくない場合は、もっと簡単な方法があります。以下のURLから必要なファイルをダウンロードすることです。
上記のURLはMozillaのPDF.jsのライブデモです。ファイルをこのようにダウンロードすれば、常にライブラリーを最新版に保てます。
Web WorkersとPDF.js
ダウンロードした2つのファイルには、PDF文書を入手、構文解析、レンダリングする方法が書かれています。pdf.jsはメインとなるライブラリーで、URLからPDF文書を入手する方法も含んでいます。しかし、PDFを構文解析、レンダリングするのは簡単な作業ではありません。実際にPDFの性質によっては、構文解析、レンダリングには他のフェーズよりも少し長い時間がかかり、このフェーズの作業が他のJavaScript機能を妨げる可能性があります。
HTML5はWeb Workersを導入しました。Web Workersは、ブラウザーのJavaScriptスレッドとは別のスレッドでコードを実行するために利用されます。PDF.jsは、構文解析やレンダリングのようなCPUに負担のかかる演算処理をメインスレッド以外に移すことでパフォーマンスを上げていますが、Web Workersに大きく依存しています。Web Workersで拡張コード処理を実行するのはPDF.jsのデフォルト設定ですが、必要に応じて解除します。
PDF.jsのPromise
PDF.jsのJavaScript APIは非常にシンプルで使いやすく、Promiseに基づいて作られています。このAPIをコールするとPromiseを返し、適切に非同期演算されます。
Hello World!
では、簡単な「Hello World!」PDF文書をレンダリングしてみます。この例で使われる文書については、このURLをチェックしてください。
http://localhost/pdfjs_learning/index.htmlからアクセスできるように、プロジェクトをローカルWebサーバーに作成します。PDF.jsはページ別ではなく1つの文書としてPDF文書を入手するためにAjaxをコールします。Ajaxのコールを指定の場所で実行するために、PDF.jsファイルをローカルWebサーバー内に配置する必要があります。ローカルWebサーバーにpdfjs_learningフォルダを作成したら、ダウンロードしたファイル(pdf.js、pdf.worker.js)もローカルWebサーバー内に配置します。そのあと、以下のコードをindex.htmlに配置します。
<!DOCTYPE html>
<html>
<head>
<title>PDF.js Learning</title>
</head>
<body>
<script type="text/javascript" src="pdf.js"></script>
</body>
</html>
見てのとおり、メインライブラリであるpdf.jsへのリンクを含めました。PDF.jsは自動的にブラウザーがWeb Workersをサポートしているかを検知し、サポートしていると判断した場合は、pdf.jsと同じ場所からpdf.worker.jsのロードしようとします。このファイルが別の場所にある場合は、メインライブラリーを含め、すぐにこのファイルをPDFJS.workerSrcプロパティを利用して設定できます。
<script type="text/javascript" src="pdf.js"></script>
<script type="text/javascript">
PDFJS.workerSrc = "/path/to/pdf.worker.js";
</script>
利用しているブラウザーがWeb Workersをサポートしていない場合、pdf.jsがWeb WorkersなしにPDF文書を構文解析、レンダリングするのに必要なすべてのコードを含んでいるので心配無用です。しかし、PDF文書によっては、pdf.jsはメインとなるJavaScript実行スレッドを停止する可能性があります。
では、なにか実際にコードを書いて「Hello World!」のPDF文書をレンダリングします。以下のコードをpdf.jsタグの下のscriptタグに配置します。
// URL of PDF document
var url = "http://mozilla.github.io/pdf.js/examples/learning/helloworld.pdf";
// Asynchronous download PDF
PDFJS.getDocument(url)
.then(function(pdf) {
return pdf.getPage(1);
})
.then(function(page) {
// Set scale (zoom) level
var scale = 1.5;
// Get viewport (dimensions)
var viewport = page.getViewport(scale);
// Get canvas#the-canvas
var canvas = document.getElementById('the-canvas');
// Fetch canvas' 2d context
var context = canvas.getContext('2d');
// Set dimensions to Canvas
canvas.height = viewport.height;
canvas.width = viewport.width;
// Prepare object needed by render method
var renderContext = {
canvasContext: context,
viewport: viewport
};
// Render PDF page
page.render(renderContext);
});
次に、body内にidをthe-canvasとした<canvas>要素を作成します。
<canvas id="the-canvas"></canvas>
<canvas>要素を作成したらブラウザーを再読み込みします。すべてのコードが正しい位置に配置されていれば、ブラウザー上にHello, world!とレンダリングされるはずです。しかし、これはただのHello, world!ではありません。レンダリングされているHello, world!は、JavaScriptを利用してブラウザー内で生成された完全なPDF文書なのです。すごいですよね!
さて、さきほどのPDF文書のレンダリングを可能にしたコードが、通常のコードとどこが異なるのか説明します。
PDFJSはブラウザーにpdf.jsファイルを読み込んだときに得られるグローバルオブジェクトです。このオブジェクトはベースオブジェクトであり、さまざまなメソッドが含まれています。
PDFJS.getDocument()はメインとなるエントリーポイントであり、他のすべての演算もここで実行されます。このメソッドはページ別ではなく1つの文書としてダウンロードするために複数のAjaxリクエストを送信し、PDF文書を非同期で入手するために利用されます。これは速いだけでなく効率的です。このメソッドに受け渡されるパラメーターはさまざまですが、最も重要なのはPDF文書を指し示すURLです。
PDFJS.getDocument()はPromiseを返します。このPromiseはPDF.jsが文書の入手が完了したとき、実行されるコードを配置するために利用する可能性があります。入手したPDF文書についての情報を含むオブジェクトは、Promiseのサクセスコールバックへ受け渡されます。例の中ではこの引数の名称をpdfとします。
文書のサイズが大きくても1つのPDF文書として入手されるので、ほんの数秒(またはほんの数分)の遅れでサクセスコールバックがコールされるだけだろうと考えるかもしれません。しかし実際には、このコールバックは最初のページのレンダリングに必要なバイト単位の情報が入手でき次第すぐに作動します。
pdf.getPage()は、PDF文書形式で個別のページを入手するのに利用されます。有効なページ番号を入力すると、getPage()はそのページを見つけ次第、要求されたページを表すpageオブジェクトを示すpromiseを返します。このpdfオブジェクトもプロパティやnumPagesがあり、PDF文書の合計ページ数を数えるために利用されます。
scaleはPDF文書のページをレンダリングする際のズームレベルです。
page.getViewport()は指定したズームレベルに対してPDF文書のページ寸法を返します。
page.render()は、PDFページをカンバスにレンダリングするためのさまざまなキーや値のペアを持つオブジェクトを要求します。今回の例では、page.getViewportメソッドから得た、Canvas要素の2dコンテキストやviewportオブジェクトを受け渡しました。
SVGを利用したレンダリング
PDF.jsは2つのレンダリングモードをサポートしています。デフォルトではCanvasをベースにしたレンダリング方式が設定されていて、こちらが人気です。しかし、SVGを利用してもPDF文書をレンダリングできます。ここでは、先に紹介したHello World!のPDF文書をSVGでレンダリングしてみます。
pdf.getPage()のサクセスコールバックを以下のコードで更新し、PDF.jsがSVGによりレンダリングされているところを見てみます。
.then(function(page) {
// Set scale (zoom) level
var scale = 1.5;
// Get viewport (dimensions)
var viewport = page.getViewport(scale);
// Get div#the-svg
var container = document.getElementById('the-svg');
// Set dimensions
container.style.width = viewport.width + 'px';
container.style.height = viewport.height + 'px';
// SVG rendering by PDF.js
page.getOperatorList()
.then(function (opList) {
var svgGfx = new PDFJS.SVGGraphics(page.commonObjs, page.objs);
return svgGfx.getSVG(opList, viewport);
})
.then(function (svg) {
container.appendChild(svg);
});
});
bodyタグの<canvas>要素を<div id="the-svg"></div>と入れ替えてからブラウザーを再読み込みします。
コードを正しく配置できていればレンダリングされたHello,world!がレンダリングされますが、今回はCanvasではなくSVGを利用しています。このページのHTMLを確認すれば、標準SVG要素を利用して完全にレンダリングがされているのが分かるはずです。
このように、PDF.jsのレンダリング方法はたくさんあります。要求に応じて、CanvasまたはSVGレンダリングのどちらでも利用できます。次では、Canvasをベースにしたレンダリングを紹介します。
テキストレイヤーのレンダリング
PDF.jsを使えば、Canvasを利用してレンダリングしたPDFページの上にあるテキストレイヤーをレンダリングできます。このレンダリングには、PDF.js GitHubからJavaScriptファイルを追加で入手する必要があります。text_layer_builder.js pluginをダウンロードしてください。さらに対応するCSSファイル、text_layer_builder.cssも入手する必要があります。両方のファイルをダウンロードし、ローカルサーバーのpdfjs_learningフォルダーに置いてください。
実際にテキストレイヤーのレンダリングに入る前に、「Hello World!」の例よりも多くの内容を含んだPDF文書を入手しましょう。これからレンダリングする文書もMozillaのライブデモから入手したものです。詳しくはここを参照してください。
この文書は複数のページがありますので、コードを少し調整する必要があります。はじめに、さきほどの例で作成した<div>タグを削除し、このタグと以下のタグを入れ替えます。
<div id="container"></div>
このコンテナーは、PDF文書の複数のページをまとめます。Canvas要素としてレンダリングされたページを配置する構造は非常にシンプルです。PDFの各ページはdiv#container内に<div>があります。<div>のid属性はpage-#{pdf_page_number}形式です。たとえば、PDF文書の最初のページにはpage-1と設定されたid属性を持つ<div>があり、12ページ目にはpage-12があります。これらの各page-#{pdf_page_number}divの中にはCanvas要素があります。
getDocument()のサクセスコールバックを次のコードと入れ替えます。http://mozilla.github.io/pdf.js/web/compressed.tracemonkey-pldi-09.pdf(またはほかの任意のオンラインPDF文書)のurlの変数を更新するのを忘れないようにしてください。
PDFJS.getDocument(url)
.then(function(pdf) {
// Get div#container and cache it for later use
var container = document.getElementById("container");
// Loop from 1 to total_number_of_pages in PDF document
for (var i = 1; i <= pdf.numPages; i++) {
// Get desired page
pdf.getPage(i).then(function(page) {
var scale = 1.5;
var viewport = page.getViewport(scale);
var div = document.createElement("div");
// Set id attribute with page-#{pdf_page_number} format
div.setAttribute("id", "page-" + (page.pageIndex + 1));
// This will keep positions of child elements as per our needs
div.setAttribute("style", "position: relative");
// Append div within div#container
container.appendChild(div);
// Create a new Canvas element
var canvas = document.createElement("canvas");
// Append Canvas within div#page-#{pdf_page_number}
div.appendChild(canvas);
var context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = viewport.width;
var renderContext = {
canvasContext: context,
viewport: viewport
};
// Render PDF page
page.render(renderContext);
});
}
});ブラウザーを再読み込みし、(新しいPDF文書をバックグラウンドでダウンロードする間)少し待ちます。文書のロードが完了したらすぐに、ブラウザーできれいにレンダリングされたPDFページがレンダリングされるはずです。これで複数のページのレンダリング方法が分かったと思いますので、今度はテキストレイヤーのレンダリング方法を見ていきます。
以下の2行をindex.htmlに追加し、テキストレイヤーのレンダリングに必要なファイルを揃えます。
<link type="text/css" href="text_layer_builder.css" rel="stylesheet">
<script type="text/javascript" src="text_layer_builder.js"></script>
PDF.jsが複数の<div>要素内でCanvas上のテキストレイヤーをレンダリングするので、これらすべての<div>要素をコンテナー要素に含めておいた方が良いです。page.render(renderContext)行を以下のコードと入れ替えれば、テキストレイヤーが有効になります。
page.render(renderContext)
.then(function() {
// Get text-fragments
return page.getTextContent();
})
.then(function(textContent) {
// Create div which will hold text-fragments
var textLayerDiv = document.createElement("div");
// Set it's class to textLayer which have required CSS styles
textLayerDiv.setAttribute("class", "textLayer");
// Append newly created div in `div#page-#{pdf_page_number}`
div.appendChild(textLayerDiv);
// Create new instance of TextLayerBuilder class
var textLayer = new TextLayerBuilder({
textLayerDiv: textLayerDiv,
pageIndex: page.pageIndex,
viewport: viewport
});
// Set text-fragments
textLayer.setTextContent(textContent);
// Render text-fragments
textLayer.render();
});
ブラウザーを再読み込みすれば、レンダリングされたPDFを閲覧するだけではなくPDFのテキストの選択、コピーもできるようになっているはずです。PDF.jsは本当にすばらしいですね!
上記のコードスニペットの重要な点を何点か挙げておきます。
page.render()はPDF.jsの他のさまざまなメソッドと同様に、PDFページのレンダリングが成功し画面にレンダリングされた時にpromiseを返します。
page.getTextContent()は、特定のページ用のテキストフラグメントを返すメソッドです。このメソッドもpromiseを返し、このpromiseのサクセスコールバックでテキストフラグメントを返します。
TextLayerBuilderは、各ページにあるpdf.getPage()からすでに入手済みのパラメーターを要求するクラスです。textLayerDivパラメーターは、特定のテキストフラグメントを表す複数の<div>を持つコンテナーとして利用されている<div>の代表的なものです。
新しく作成されたインスタンスであるTextLayerBuilderには、2つの重要なメソッドがあります。1つはsetTextContent()で、もう1つはpage.getTextContent()とrender()が返すテキストフラグメントを設定するために利用されます。これらはテキストレイヤーをレンダリングするのに利用されます。
ご覧のとおり、textLayerからtextLayerDivまでをCSSクラスに割り当てています。このクラスは、必ずテキストフラグメントがCanvas要素の上に無理なくフィットし、ユーザーがテキストを自然に選択、コピーできるスタイルになっています。
拡大・縮小
PDF.jsを利用すれば、PDF文書の拡大・縮小も制御できます。実際に、拡大・縮小はとても簡単で、scale値を更新すればよいだけです。拡大・縮小するには、望みどおりにscale値を上げるかまたは下げてください。これは、みなさんへの課題として残しておきます。でも、ぜひトライしてください。
最後に
PDF.jsは、JavaScriptを使ったブラウザーにもともと備わっているPDFレンダリング機能の代わりになる、融通の利くすばらしいツールです。このAPIは簡単、正確、簡潔であり、思いどおりに使えます。
(原文:Custom PDF Rendering in JavaScript with Mozilla’s PDF.Js)
[翻訳:中村文也]
[編集:Livit]